Algorithmen des maschinellen Lernens aus der Sicht eines Erkennungsentwicklers
 Nach einigen Monaten bei Exeon und nachdem ich mich bisher hauptsächlich auf die Entwicklung von statischen Verhaltenserkennungen konzentriert habe, teile ich einige Erkenntnisse über bestimmte Eigenschaften bei der Entwicklung von Erkennungen auf der Grundlage von Machine Learning Algorithmen. Letztendlich ändert sich dadurch die Art und Weise, wie wir an die Erstellung von Erkennungen herangehen und welche Fragen während der Entwicklung beantwortet werden müssen.
Nach einigen Monaten bei Exeon und nachdem ich mich bisher hauptsächlich auf die Entwicklung von statischen Verhaltenserkennungen konzentriert habe, teile ich einige Erkenntnisse über bestimmte Eigenschaften bei der Entwicklung von Erkennungen auf der Grundlage von Machine Learning Algorithmen. Letztendlich ändert sich dadurch die Art und Weise, wie wir an die Erstellung von Erkennungen herangehen und welche Fragen während der Entwicklung beantwortet werden müssen.
Wir bei Exeon nutzen Algorithmen des maschinellen Lernens und deren Baselining-Funktionen für unsere NDR-Plattform (Network Detection & Response) ExeonTrace. Die Anwendung von ML reicht von Erkennungen für Algorithmen die Domains generieren bis hin zur Analyse des Verkehrsvolumens, der Erkennung von Command-and-Control-Kanälen und der Erkennung von interner Weiterverbreitung (Lateral Movement). Über die allgemeinen Vorteile beim Einsatz von ML haben wir bereits in unserem Blogbeitrag Die Zukunft der Netzwerksicherheit: Prädiktive Analytik und ML-gesteuerte Lösungen geschrieben.
Neben der allgemeinen Diskussion über die Vorteile und Herausforderungen beim Einsatz von Algorithmen des maschinellen Lernens für die Erkennung von Bedrohungen sehen sich die Detection Engineers bei der Erstellung von Erkennungen mit ihren eigenen Vorteilen und Herausforderungen konfrontiert. In diesem Blogbeitrag werden diese Aspekte aus der Sicht eines Erkennungsentwickler umrissen und die entsprechenden Fragen, die sich bei der Entwicklung von Anwendungsfällen stellen, erläutert.
Detection Engineering ist der Prozess der Identifizierung relevanter Bedrohungen und der Entwicklung, Verbesserung, Überprüfung und Abstimmung von Erkennungsfunktionen zur Abwehr dieser Bedrohungen.
Was bedeutet es, ML-Algorithmen für die Erkennungsentwicklung zu verwenden?
Bis vor kurzem und auch heute noch verlassen sich viele Sicherheitsteams bei der Erkennung von Bedrohungen auf statische Signaturen. Entweder mit einem IDS zur Netzwerkanalyse oder mit statischen Verhaltenserkennungen auf der Grundlage von Endpunktprotokollen. IoCs, IoAs, Yara- oder Sigma-Regeln werden alle verwendet, um bösartiges Verhalten zu erkennen. Mit immer mehr Daten wird es schwierig, den Überblick zu behalten, und es wird schwierig, alle Quellen und Angriffsmuster mit individuellen Regeln abzudecken. Um diese Herausforderungen zu meistern, helfen Algorithmen des maschinellen Lernens dabei, die Perspektive bei der Erkennungsentwicklung zu wechseln. Wenn wir ML einsetzen, können wir den guten Zustand lernen und Abweichungen erkennen.
Überwachte und unüberwachte Algorithmen für maschinelles Lernen
Algorithmen des maschinellen Lernens können in zwei Gruppen unterteilt werden: überwachte und nicht überwachte Algorithmen. Beide haben Vorteile und einige Einschränkungen in ihrer Anwendung.
Die überwachten Algorithmen werden im Voraus trainiert, um bekannt gute und bekannt schlechte Merkmale zu erkennen. Bei unüberwachten Algorithmen definieren wir einige wichtige Merkmale, auf die wir achten müssen, und lernen diese Basislinie innerhalb des Netzwerks, um Ausreißer ohne statische Indikatoren für bekannte schlechte Merkmale zu erkennen.
Unüberwachte Algorithmen verwenden Baselining, das heißt, sie lernen den guten Zustand der Infrastruktur. Sie können ihre Basislinie dynamisch an die Umgebung des Kunden anpassen. In unserem Kontext konzentrieren wir uns auf die Netzwerkkommunikation und suchen dann nach Ausreißern oder ungewöhnlichem Verhalten, das vom Normalzustand abweicht. Am Ende läuft alles auf (Netzwerk-)Statistik, Berechnung von Wahrscheinlichkeiten, Zeitanalyse und Clustering (unter Berücksichtigung von Peer-Gruppen) hinaus.
Die erste Frage wird also immer sein, ob wir überwachtes oder unüberwachtes maschinelles Lernen verwenden. Beide haben Vorteile für ihre Anwendung, und diese müssen während der Entwicklung bewertet werden.
Wie die Erkennungsentwicklung mit ML eine Neuformulierung der Fragen erfordert
Die Erkennungsentwicklung, die sich auf Algorithmen des maschinellen Lernens stützt, erfordert eine Neuformulierung wichtiger Fragen während der Entwicklung von Anwendungsfällen. Bei vielen Anwendungsfällen wechseln wir die Perspektive von dem, was bösartig ist, zu dem, was normal aussieht. Dies ermöglicht eine größere Offenheit gegenüber Variationen im bösartigen Verhalten. Wir gehen nicht täglich zum Arzt, aber wir bemerken Veränderungen unserer Körpertemperatur, Müdigkeit usw. im Vergleich zum Normalzustand. Von Zeit zu Zeit ist jedoch eine gründliche Überprüfung erforderlich, wie eine Kompromissbewertung in der IT-Sicherheit. Daher müssen die Erkennungsingenieure die Ähnlichkeiten zwischen den Angriffsmustern, ihre Merkmale und die Basislinie, für die Ausreißer erkannt werden müssen, verstehen. Im Gegensatz zu traditionellen Erkennungsansätzen geht es mehr darum zu verstehen, was gut und normal ist, als sich nur auf das zu konzentrieren, was schlecht ist. Zusammenfassend lässt sich sagen, dass das Verständnis des Kontexts und der Basislinie eines Systems oder einer Infrastruktur die Erkennung robuster macht.
Die Erkennungsentwicklung, die sich auf Algorithmen des maschinellen Lernens stützt, erfordert eine Neuformulierung wichtiger Fragen während der Entwicklung von Anwendungsfällen. Die Erkennungsentwicklung, die sich auf Algorithmen des maschinellen Lernens stützt, erfordert eine Neuformulierung wichtiger Fragen während der Entwicklung von Anwendungsfällen.
Ich werde nun einige Einblicke in einige Aspekte der Anwendungsfallentwicklung geben und aufzeigen, welche Fragen sich bei der Verwendung von unüberwachtem maschinellem Lernen stellen.
- Festlegung des Ziels: Wir müssen das Ziel eines Anwendungsfalls für die Erkennung definieren. Wir legen das Angriffsmuster, das wir überwachen möchten, explizit fest. Beispiel: In einigen bestimmten Netzwerksegmenten wird nur eine Teilmenge der Netzwerkdienste regelmäßig genutzt. Wir wollen herausfinden, wie viele Anfragen für einen bestimmten Infrastrukturservice (z.B. Benutzeranmeldung) normalerweise gestellt werden, und Veränderungen im Vergleich zu diesem Normalzustand erkennen.
- Extrahieren von Merkmalen, um den Normalzustand zu lernen: Wir müssen die Merkmale des Anwendungsfalls, den wir erkennen möchten, studieren und verstehen (wie bei der traditionellen Erkennungsentwicklung). Darüber hinaus studieren wir den Normalzustand, den allgemein bekannten guten Zustand, um die Eigenschaften für die Algorithmen zu definieren. Mit diesen wird der Normalzustand gelernt. Somit sind wir in der Lage bei Ausreißern (bösartigem Verhalten) Alarm zu schlagen. Wir müssen nicht festlegen, was genau der Schwellenwert ist, sondern nur die Parameter definieren, um diese Basislinie zu lernen. Der Schwellwert wird dynamisch angepasst.
- Definierung des Vergleichsmodell: Wir müssen entscheiden, ob wir eine Anomalie auf der Grundlage eines Vergleichs zwischen dem aktuellen Verhalten eines Clients und seinem früheren Verhalten auslösen wollen oder ob wir Ausreißer eines Clients beim Vergleich seines Verhaltens mit dem seiner Kollegen (Referenzgruppe) erkennen wollen. Wir können Beliebtheitsschwellen definieren, d.h. ob und wie das Verhalten anderer Clients bei der Analyse berücksichtigt werden soll.
- Definierung des Lernfenster: Ein wichtiger Faktor ist das Zeitfenster für die Lernphase, sozusagen der Zeitraum, in dem der gute Zustand erlernt werden soll. Dies beeinflusst die Schwanungsbreite des gelernten Verhaltens.
Um die Entwicklung von Erkennungsmethoden zu beschleunigen, können beispielsweise neue unüberwachte Erkennungen mithilfe eines generischen Anwendungsfall-Frameworks erstellt werden, das ML-Funktionen für Erkennungsingenieure zugänglicher macht, ohne dass sie ML-Entwickler sein müssen.
Wie man das Leben von Sicherheitsanalysten einfacher machen kann
Darüber hinaus müssen Erkennungsingenieure und ML-Entwicklungsteams bedenken, was es für Cybersicherheitsanalysten bedeutet, die sich die von diesen Algorithmen ausgelösten Warnungen und Anomalien ansehen. Hier ist die Erklärung von Anomalien von größter Bedeutung. Heutzutage liefern Sicherheitstools manchmal nur die Information, dass die ML-Engine XY entdeckt hat, aber es ist den Analysten nicht bekannt, was genau entdeckt wurde. In ExeonTrace stellen wir die benötigten Informationen an verschiedenen Stellen zur Verfügung, entweder immer mit dem genauen Algorithmusnamen und Kontextinformationen zu einer Anomalie oder mit den Baselining-Informationen direkt zur Anomalie.
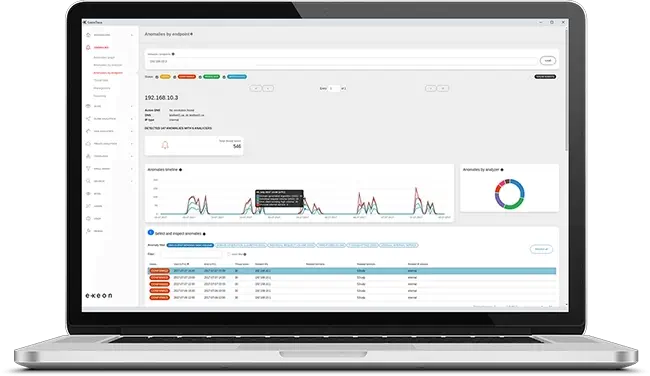
Wo Kunden ML für ihre eigene Erkennung verwenden können
Intern können wir überwachte und unüberwachte Algorithmen verwenden, während die Kunden unüberwachte Algorithmen für ihre eigenen Erkennungstests verwenden können. ExeonTrace bietet eine leistungsstarke Funktion zur Erkennung von Ausreißern, für die Kunden nur angeben müssen, welche Datenpunkte berücksichtigt werden sollen, und Anomalien für alle Ausreißer erhalten.
Was ML-Algorithmen für das Testen und Verifizieren bedeuten
Ein wichtiger Aspekt der Erkennungsentwicklung ist die Test- und Verifizierungsphase neuer Erkennungen. Und hier gibt es einen weiteren Aspekt, der sich sehr von den traditionellen Erkennungstests unterscheidet. Bisher konnten wir Tests gegen bestimmte Beweise oder Protokollinformationen durchführen und erhielten eine direkte Rückmeldung: "schlecht" vs. "nicht schlecht", "gefunden" vs. "nicht gefunden". Wenn es um Algorithmen für maschinelles Lernen und die Verwendung von zeitlichen Unterschieden, Clustering, Popularität, Kontext und mehreren Merkmalen geht, ist das Testen von ML-Algorithmen eine Herausforderung für sich. Daher werden gute Datensätze mit realen oder synthetischen Daten benötigt, um die erforderliche Grundlage zu schaffen, auf der Tests aufgebaut werden können.

Quelle: David J. Bianco
Unter Verwendung der Schmerzpyramide (Pyramid of Pain) zielen robuste Algorithmen des maschinellen Lernens auf die Spitze der Pyramide ab, aber im Hinblick auf die Erkennungstests liegt sie auch an der Spitze, was bedeutet, dass sie im Vergleich zu traditionellen Erkennungstests schwieriger ist.
Zusammenfassend lässt sich sagen, dass die Erkennungsentwicklung unter Verwendung von Algorithmen des maschinellen Lernens über den traditionellen Ansatz der Erkennungsentwicklung hinausgeht, bei dem man sich auf bekanntes schlechtes Verhalten konzentriert, sondern auf das Erlernen der Basislinie für bekanntes gutes Verhalten (guter Gesundheitszustand) und auf die Frage, wie wir diese Basislinie nutzen können, um bei abnormalem Verhalten Alarm zu schlagen. Die Fragen, mit denen Erkennungsentwickler während der Entwicklung konfrontiert werden, sind unterschiedlich, aber die Bereitstellung eines guten ML-Frameworks wird den Erkennungsentwicklern und den Sicherheitsteams der Kunden den Zugang erleichtern.
ML-gesteuerte Bedrohungserkennung in Aktion
Die in der Schweiz hergestellte Netzwerksicherheitslösung ExeonTrace liefert ein vollständiges Bild über gutes und schlechtes Verhalten, da sie auf ML-Algorithmen basiert, die speziell für die Analyse von verschlüsselten Daten entwickelt wurden, die mit herkömmlichen Network Detection & Response (NDR)-Lösungen nicht analysiert werden können.
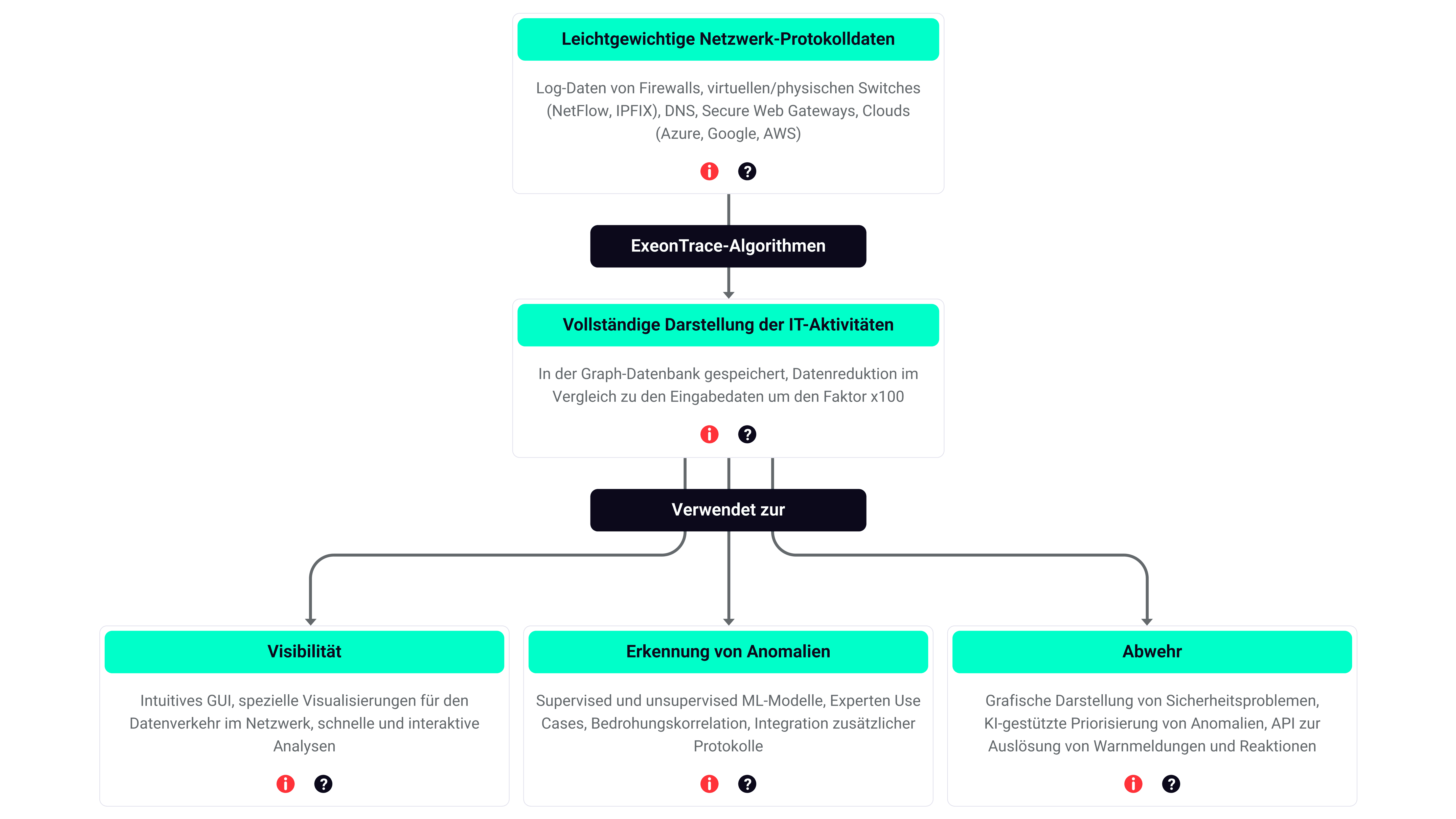
Durch den Einsatz fortschrittlicher ML-Algorithmen, die den Netzwerkverkehr und die Anwendungsprotokolle analysieren, bietet ExeonTrace Unternehmen eine schnelle Erkennung und Reaktion selbst auf die raffiniertesten Cyberangriffe.
Buchen Sie eine kostenlose Demo und erfahren Sie, wie ExeonTrace ML-Algorithmen einsetzt, um Ihr Unternehmen widerstandsfähiger gegen Cyberangriffe zu machen - schnell, zuverlässig und völlig hardwarefrei.

Author:
Andreas Hunkeler
Head of Professional Services
email:
andreas.hunkeler@exeon.com
Share:
Published on:
28.06.2023